Reinforcement Learning Base Knowledge Graph
Note
View the complete implementation in Google Colab:
Prerequisites
Software Requirements
Python 3.8+
Neo4j Community Edition 5.26.0 (or higher)
Python Dependencies
pip install neo4j
pip install openai
pip install typing
pip install pathlib
Neo4j Setup
Installation
Download Neo4j Community Edition 5.26.0 for Windows and extract to C:\Program Files
Starting Neo4j Server
Open Command Prompt as Administrator
Navigate to Neo4j installation directory:
cd "C:\Program Files\neo4j-community-5.26.0-windows\neo4j-community-5.26.0"
Start Neo4j server:
.\bin\neo4j console
Access Neo4j Browser interface:
Open your web browser and navigate to: http://localhost:7474/browser/
Initial Setup
When accessing Neo4j Browser for the first time:
Default connection settings:
Connect URL: neo4j://localhost:7687
Database: neo4j
Default credentials:
Username: neo4j
You’ll be prompted to change the default password
Knowledge Graph Construction
Entity Extraction Process
The initial phase involves extracting reinforcement learning concepts from textbook content. This process is implemented through the RLEntityExtractor class.
Entity Extraction Flow
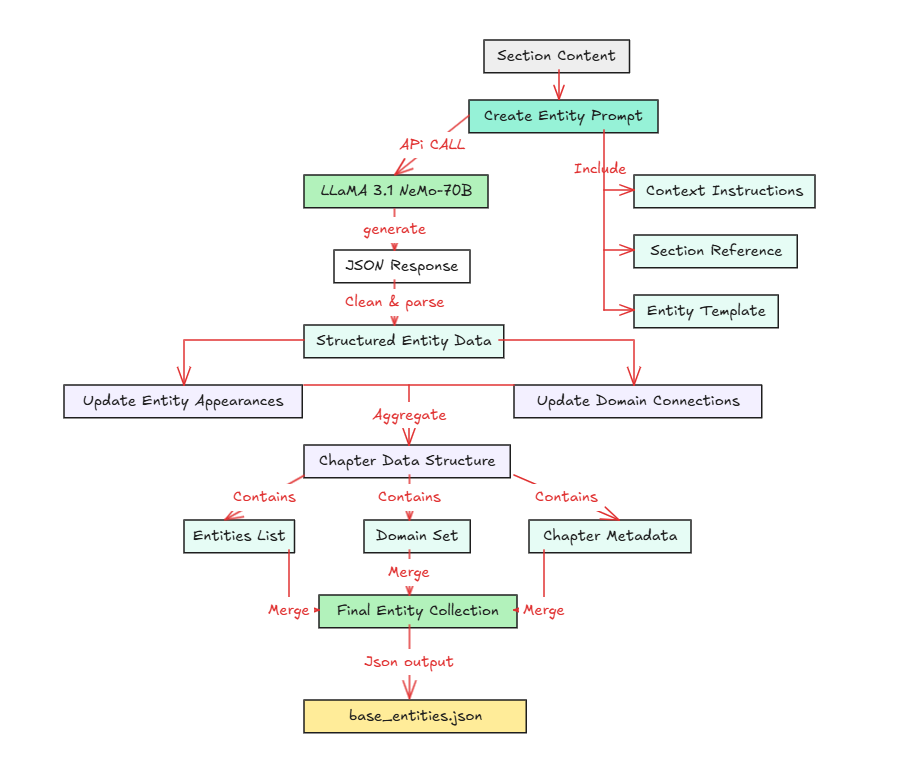
Entity Extraction Process
Core Implementation
Initialization
The extractor is initialized with API configuration and tracking structures:
def __init__(self, api_key: str = None):
self.client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key=api_key or "your_api_key"
)
self.entity_appearances = defaultdict(set)
self.domain_connections = defaultdict(set)
Prompt Engineering
The prompt template is crucial for consistent entity extraction:
def create_extract_prompt(self, section_text: str, chapter: str, section: str) -> str:
return f"""Extract key RL entities and their relationships from this text section.
Focus on core concepts, domains, and clear relationships. Format as JSON:
{{
"entities": [
{{
"id": "unique_snake_case_id",
"name": "Full Concept Name",
"type": "concept|algorithm|method|principle|domain",
"definition": "Clear, precise definition under 50 words",
"domains": ["domain1", "domain2"],
"properties": [
{{
"name": "property_name",
"value": "property_value",
"type": "characteristic|parameter|constraint|requirement"
}}
],
"source": {{
"chapter": "{chapter}",
"section": "{section}",
"context": "Brief context"
}}
}}
]
}}
Text to analyze:
{section_text}"""
Section Processing
Individual sections are processed using the LLM:
def process_section(self, section_text: str, chapter: str, section: str) -> Dict:
try:
completion = self.client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-70b-instruct",
messages=[{
"role": "user",
"content": self.create_extract_prompt(section_text, chapter, section)
}],
temperature=0.3,
max_tokens=2048
)
if completion.choices:
response_text = completion.choices[0].message.content
extracted = self.clean_json_response(response_text)
if 'entities' in extracted:
self.update_cross_references(extracted['entities'], chapter)
return extracted
return {}
except Exception as e:
print(f"Error processing section: {e}")
return {}
Cross-Reference Management
Tracking entity appearances and domain connections:
def update_cross_references(self, entities: List[Dict], chapter: str) -> None:
for entity in entities:
entity_id = entity['id']
self.entity_appearances[entity_id].add(chapter)
if 'domains' in entity:
for domain in entity['domains']:
self.domain_connections[domain].add(entity_id)
Chapter Processing
Complete chapter processing workflow:
def process_chapter_file(self, file_path: Path) -> Dict:
try:
with open(file_path, 'r', encoding='utf-8') as f:
sections = json.load(f)
chapter_data = {
'chapter_id': file_path.stem,
'entities': [],
'relationships': [],
'domains': set(),
}
for section_id, content in sections.items():
print(f"Processing {file_path.stem} - {section_id}")
section_data = self.process_section(
content,
chapter=file_path.stem,
section=section_id
)
if section_data:
chapter_data['entities'].extend(section_data.get('entities', []))
chapter_data['relationships'].extend(section_data.get('relationships', []))
chapter_data['domains'].update(section_data.get('domains_discussed', []))
chapter_data['domains'] = list(chapter_data['domains'])
return chapter_data
except Exception as e:
print(f"Error processing chapter file {file_path}: {e}")
return {}
Output Format and Structure
The entity extraction process produces a structured JSON output. Here’s an example of extracted entities:
{
"entities": {
"reinforcement_learning": {
"id": "reinforcement_learning",
"name": "Reinforcement Learning",
"type": "domain",
"definition": "A computational approach to understanding and automating goal-directed learning and decision making.",
"domains": [
"artificial_intelligence",
"machine_learning",
"psychology",
"neuroscience"
],
"properties": [
{
"name": "characteristics",
"value": "trial-and-error search, delayed reward, emphasis on learning from interaction with environment",
"type": "characteristic"
}
],
"source": [
{
"chapter": "1",
"section": "1.1",
"context": "Introduction to Reinforcement Learning"
},
{
"chapter": "Introduction to Machine Learning",
"section": "Subfields of ML",
"context": "RL as a part of ML"
}
]
}
}
}
Notes about the output:
Entity Structure:
Unique identifier (snake_case)
Descriptive name
Entity type classification
Clear, concise definition
Associated domains
Characteristic properties
Source references
Source Tracking:
Multiple appearances across chapters
Section-level granularity
Contextual information
Hierarchical organization
Domain Classification:
Cross-domain relationships
Multiple domain associations
Domain hierarchy preservation
Property Format:
Named characteristics
Typed attributes
Value descriptions
Property categorization
Relationship Extraction Process
The second phase focuses on extracting meaningful relationships between entities using a layered approach, implemented through the LayeredRelationshipExtractor class.
Implementation Details
Layer Classification
Each entity is classified into one of four layers based on its type:
def determine_layer(self, entity_data: Dict) -> str:
if 'type' in entity_data:
entity_type = entity_data['type'].lower()
# Mathematical and theoretical concepts
if entity_type in ['theorem', 'equation', 'principle', 'proof',
'definition', 'framework', 'concept']:
return 'foundation_layer'
# Methods and approaches
elif entity_type in ['value_based', 'policy_based', 'model_based',
'hybrid', 'method']:
return 'method_layer'
# Algorithms and implementations
elif entity_type in ['algorithm', 'base_algorithm', 'variant']:
return 'algorithm_layer'
# Applications and domains
elif entity_type in ['field', 'benchmark', 'use_case', 'domain']:
return 'application_layer'
return 'foundation_layer'
Relationship Prompt Engineering
The prompt is structured to consider layer-specific relationships:
def create_relationship_prompt(self, entity_id: str, entity: Dict,
all_entities: Dict) -> str:
source_layer = self.determine_layer(entity)
entities_by_layer = {
'foundation_layer': [],
'method_layer': [],
'algorithm_layer': [],
'application_layer': []
}
for eid, e in all_entities.items():
if eid != entity_id:
layer = self.determine_layer(e)
entities_by_layer[layer].append({
'id': eid,
'name': e['name'],
'type': e.get('type', '')
})
Relationship Types
Relationships are categorized by direction:
up: Connections to higher layers
down: Connections to lower layers
same: Within-layer relationships
across: Cross-layer non-hierarchical relationships
Common relationship patterns:
Foundation → Method: "enables", "provides basis for"
Method → Algorithm: "is implemented by", "guides"
Algorithm → Application: "is applied to", "solves"
Same layer: "relates to", "extends", "similar to"
Cross-layer: "inspired by", "analogous to"
Statistics Tracking
The system maintains detailed statistics about layer connections:
layer_statistics = {
'foundation_layer': {'total': 0, 'connected': 0},
'method_layer': {'total': 0, 'connected': 0},
'algorithm_layer': {'total': 0, 'connected': 0},
'application_layer': {'total': 0, 'connected': 0}
}
layer_connections = {
'up': 0,
'down': 0,
'same': 0,
'across': 0
}
Relationship Structure
Each extracted relationship follows this format:
{
"source": "entity_id",
"source_layer": "layer_name",
"target": "target_entity_id",
"target_layer": "layer_name",
"type": "descriptive_relationship_type",
"direction": "up|down|same|across",
"evidence": {
"text": "exact text snippet showing relationship",
"location": "definition|property|source"
}
}
Output Generation
The final output includes relationships and comprehensive statistics:
output = {
"relationships": unique_relationships,
"metadata": {
"total_relationships": len(unique_relationships),
"relationship_types": sorted(list(set(rel['type']
for rel in unique_relationships))),
"total_entities_involved": len(connected_entities),
"layer_statistics": layer_statistics,
"layer_connections": layer_connections
}
}
Relationship Examples
Here are examples of different types of relationships extracted:
Same-Layer Relationship (Foundation):
{
"source": "dopamine",
"source_layer": "foundation_layer",
"target": "reward_signals",
"target_layer": "foundation_layer",
"type": "relates to",
"direction": "same",
"evidence": {
"text": "A neurotransmitter involved in reward processing ... in the mammalian brain.",
"location": "definition"
}
}
Up-Direction Relationship:
{
"source": "associative_search",
"source_layer": "foundation_layer",
"target": "temporal_difference_learning",
"target_layer": "method_layer",
"type": "enables",
"direction": "up",
"evidence": {
"text": "Associative Search involves trial-and-error learning, a key aspect of Temporal-Difference Learning.",
"location": "definition"
}
}
These examples demonstrate:
Different types of layer interactions
Various relationship types
Evidence-based connections
Directional relationships
Domain-specific associations
Knowledge Graph Building
Now that we have entities.json and relationships.json we will build the base knowledge graph in Neo4j, converting the extracted entities and relationships into a queryable graph database.
Core Implementation
Database Connection
Configuration of Neo4j connection with proper authentication:
def __init__(self, uri="bolt://localhost:7687", user="neo4j", password="password"):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
Node Creation
Special handling for different node types:
def create_node(self, tx, entity_id, entity_data):
# Convert properties to string array
properties_list = []
if entity_data.get('properties'):
for prop in entity_data['properties']:
prop_str = f"{prop['name']}: {prop['value']}"
properties_list.append(prop_str)
# Node properties structure
node_props = {
'id': entity_id,
'name': entity_data['name'],
'type': entity_data['type'],
'definition': entity_data['definition'],
'domains': entity_data.get('domains', []),
'properties': properties_list
}
# Dynamic label creation
type_label = ''.join(c for c in entity_data['type'].title()
if c.isalnum())
# Different handling for domain nodes
if entity_data['type'].lower() == 'domain':
query = """
MERGE (n:Domain {id: $id})
SET n = $node_props
"""
else:
query = f"""
MERGE (n:Concept:{type_label} {{id: $id}})
SET n = $node_props
"""
Relationship Creation
Establishing connections between nodes:
def create_relationships(self, tx, relationships_data):
relationships = relationships_data.get('relationships', [])
for rel in relationships:
# Clean relationship type for Neo4j
rel_type = rel['type'].upper()\
.replace(' ', '_')\
.strip('_')
query = f"""
MATCH (source)
WHERE source.id = $source
MATCH (target)
WHERE target.id = $target
MERGE (source)-[r:{rel_type}]->(target)
SET r.source_layer = $source_layer
SET r.target_layer = $target_layer
SET r.direction = $direction
"""
Index Creation
Optimizing graph performance with indices:
def create_indices(self, tx):
queries = [
"CREATE INDEX concept_type_idx IF NOT EXISTS FOR (n:Concept) ON (n.type)",
"CREATE INDEX concept_name_idx IF NOT EXISTS FOR (n:Concept) ON (n.name)",
"CREATE INDEX concept_id_idx IF NOT EXISTS FOR (n:Concept) ON (n.id)",
"CREATE INDEX domain_id_idx IF NOT EXISTS FOR (n:Domain) ON (n.id)",
"CREATE INDEX domain_name_idx IF NOT EXISTS FOR (n:Domain) ON (n.name)"
]
for query in queries:
tx.run(query)
Metadata Addition
Enriching the graph with analytics:
def add_metadata(self, tx):
queries = [
# Degree centrality
"""
MATCH (n)
WHERE n:Concept OR n:Domain
SET n.degree = COUNT {(n)--()}
""",
# In-degree
"""
MATCH (n)
WHERE n:Concept OR n:Domain
SET n.in_degree = COUNT {(n)<--()}
""",
# Out-degree
"""
MATCH (n)
WHERE n:Concept OR n:Domain
SET n.out_degree = COUNT {(n)-->()}
"""
]
for query in queries:
tx.run(query)
Usage Example
Building the complete knowledge graph:
def main():
ENTITIES_FILE = "entities.json"
RELATIONSHIPS_FILE = "relationships.json"
graph = RLKnowledgeGraph()
try:
graph.build_graph(ENTITIES_FILE, RELATIONSHIPS_FILE)
finally:
graph.close()